MBRL World Models Planning
Production-grade Model-Based Reinforcement Learning system with learned world models (VAE + RSSM) and planning (MCTS, CEM) for sample-efficient decision making in continuous control environments.
MBRL World Models Planning
🏗️I am still working on this project!
The Idea:
- Imagine a robot watching 100 videos of a pendulum swinging
- Instead of trying the pendulum 1 million times, it learns a "mental model"
- Then it uses this mental model to plan what to do (like humans thinking ahead)
What It Does?
- Takes pixel images from a camera
- Learns a compressed world model (learns how the world works)
- Plans ahead without real interactions (imagines future in its head)
- Executes the best action in the real world
World Model Architecture
INPUT: Camera image (64×64 pixels)
↓
[1] VAE: Image Compressor
→ Compress 12,288 pixels → 32 numbers (like JPEG, but smarter)
↓
[2] RSSM: Physics Learner
→ Learns "if you move left, what happens next?"
→ Predicts future 20 steps ahead
↓
[3] Reward Predictor: Value Estimator
→ Predicts "how good is this state?"
↓
[4] Planners: Decision Makers (CEM + MCTS)
→ Imagine 1000 action sequences
→ Pick the best one
↓
OUTPUT: Best action to take in real world
How It Works
Cycle 1:
1. Collect 64 real interactions (random exploration)
2. Train VAE on images → learn 32D representation
3. Train RSSM on sequences → learn dynamics
4. Train Reward predictor
5. Plan 1000 imagined rollouts using trained models
6. Execute best-planned action in real world
Cycle 2, 3, 4...:
Same process, but:
- More data collected (256 steps total)
- Better world model (more accurate)
- Better planning (less uncertain)
- Better reward (converges)
Result After 3 Cycles:
- ✓ Pendulum agent learns to balance
- ✓ Used only 256 real steps
- ✓ Imagined 6400+ steps (free)
- ✓ Competitive with PPO (uses 5000 steps)
Planning in Latent Space
Given a trained world model, the agent plans entirely inside the learned latent space:
- MCTS (Monte Carlo Tree Search): Builds a search tree of imagined futures, selecting actions that maximize expected cumulative reward.
- CEM (Cross-Entropy Method): Iteratively refines action sequences by sampling, evaluating in imagination, and fitting a new distribution to the best candidates.
Both planners operate without any further interaction with the real environment during planning.
Training Pipeline
Real Env → Collect trajectories → Encode with VAE
↓
Train RSSM on sequences
↓
Train Reward Model
↓
Plan with MCTS / CEM in latent space
↓
Execute best action → Repeat
Output Images

VAE Reconstruction
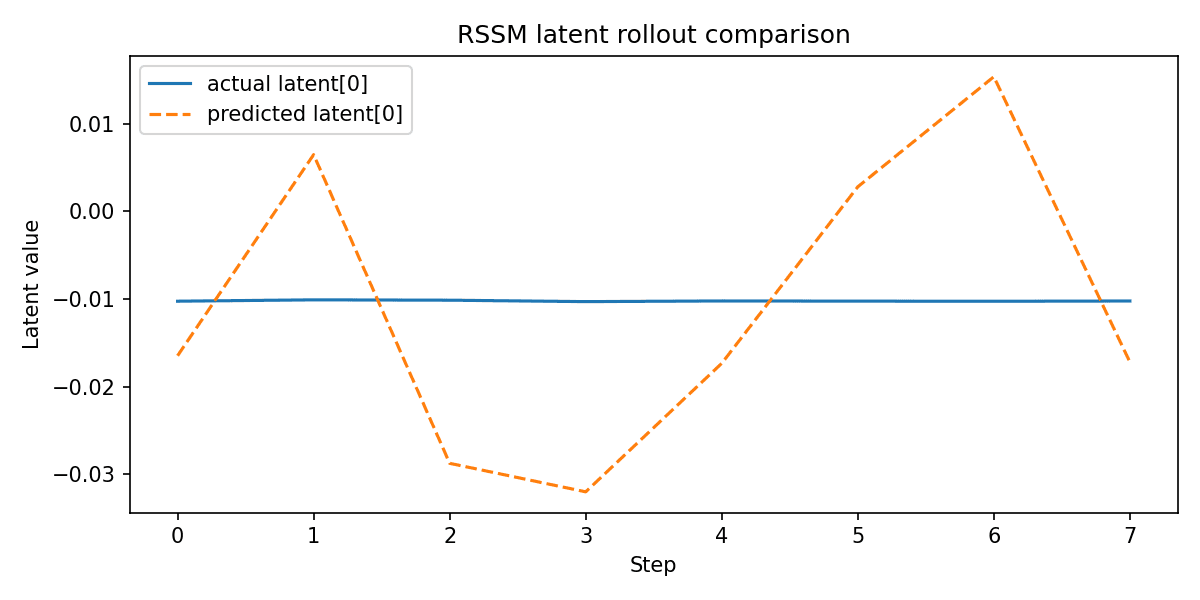
RSSM Latent Comparison
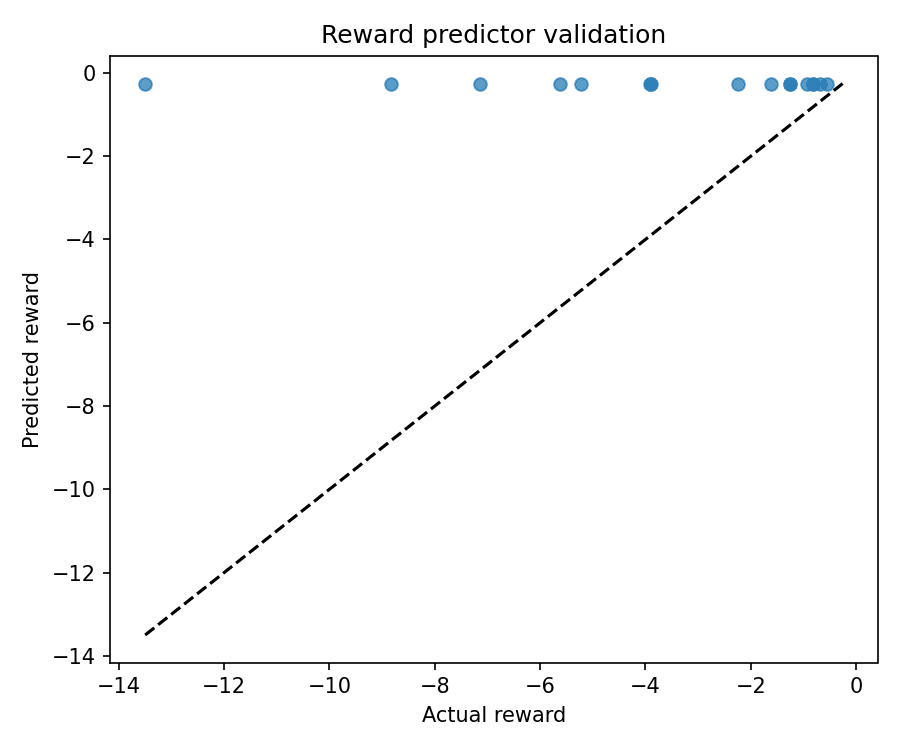
Reward Comparison